IT infrastructure monitoring
High availability/failover, security and performance are certainly the quality benchmarks for an IT operation.
Datacenter failures - the norm?
High availability/failure safety, security and performance are certainly the quality benchmarks for an IT operation. The classic day-to-day IT business finds itself constantly challenged with the dynamics of all the demands and developments placed on it externally.
For example, the regular Windows updates occasionally cause server services to fail, the discovery of security gaps immediately reveals new threats in the IT landscape, hard disks or server fans fail due to batch-related reasons and the 10-year-old refrigeration system of the datacenter has a leak and loses refrigerant. The typical normal of a planned IT working day.
On the other hand, there is usually an IT operations team that is up to its ears in project issues and now literally has to extinguish fires as they start before they turn into major fires.
Every IT professional is probably familiar with these days in practice, where on a Friday afternoon, it feels as if one malfunction follows the next and ensures that the weekend is significantly delayed.
A consistent high availability concept prevents a failure of IT services or the datacenter in most cases. Nevertheless, there is an urgent need for action, as the aim is to restore the redundancy and high availability status as quickly as possible. A second failure would then usually have a direct impact on operations, and one would like to know that one's infrastructure and systems are back in a safe state before the weekend in order to be able to sleep peacefully.
It is worth mentioning that, looking back at the last two years 2020 & 2021, the main causes of datacenter failures were to be found in the area of supply infrastructure. In 2021, 69% of the DC operators surveyed stated that they had experienced a relevant outage, 44% of which were associated with image and financial damage. It is noteworthy that the power supply (43%) and the air conditioning (14%), i.e. the supply infrastructure, were the primary reasons for failures.
However, another survey from 2020 shows an aspect that could have prevented the above-mentioned failures from occurring in the first place. Here, 91% of the respondents in 2020 state that they have had a serious disruption in their datacenter, but only 34% of them use monitoring with remote access. This leads to the assumption that these failures could have been avoided or at least reduced in the course of damage and disruption with monitoring and alarm management at infrastructure level?
Sources of the survey:
- Quelle LanLine Ausfallbilanz Rechenzentren 2021
- Quelle Datacenter Insider: Die Rechenzentrumsausfälle im Jahr 2020
Levels of monitoring
Just as the business processes of a company are hierarchically based on applications and the underlying infrastructure, comprehensive monitoring also requires the recording of all these levels.
It is important to find tools for each of these levels that meet the company's needs and requirements and that also provide interfaces and possible recording tools for the infrastructure used. Finding a tool that covers all areas equally will hardly be possible in the case of individual infrastructures. Experience has shown that several tools can be found here whose specialisation focuses on one of these levels.
Challenges and added value of monitoring
The increasing complexity of the infrastructure and the lack of personnel in many IT operations unfortunately often lead to monitoring not being kept up to date or only being used very superficially. The added value of monitoring from this unloved role is often still underestimated. In addition to the resulting transparency in the operation of the systems, the establishment and administration of a monitoring system inevitably entails dealing with the established infrastructure. To a certain extent, the monitoring system also has the function of documentation, even if it cannot replace it in all respects, but it supplements schemas with live and historical data.
The question of the appropriate tool for the specific IT landscape and individual needs is essential and far-reaching.
In practice, it has been shown that systems that follow an open interface concept can prove to be sustainable and a flexible solution for a company.
Starting in the area of datacenter monitoring, the sensors available on the market and the infrastructure systems based on building technology already result in a broad number of interfaces whose data point acquisition can already be the first hurdle. Here, one often encounters classic binary switching contacts that provide operating, warning and fault messages, as well as typical fieldbus systems such as KNX, Modbus and BACnet.
In addition, sensors that belong to the IoT segment are increasingly being used. Here, the familiar SNMP protocol is used more frequently, but also increasingly the lightweight MQTT protocol or OPC UA.
At the level of IT infrastructure monitoring, the well-known interfaces SNMP, WMI, IPMI and various http-based APIs are used from a certain standard. In addition, the manufacturers of monitoring solutions offer data collection tools (agents) for the established operating systems, which collect the necessary data and make it available to the monitoring system.
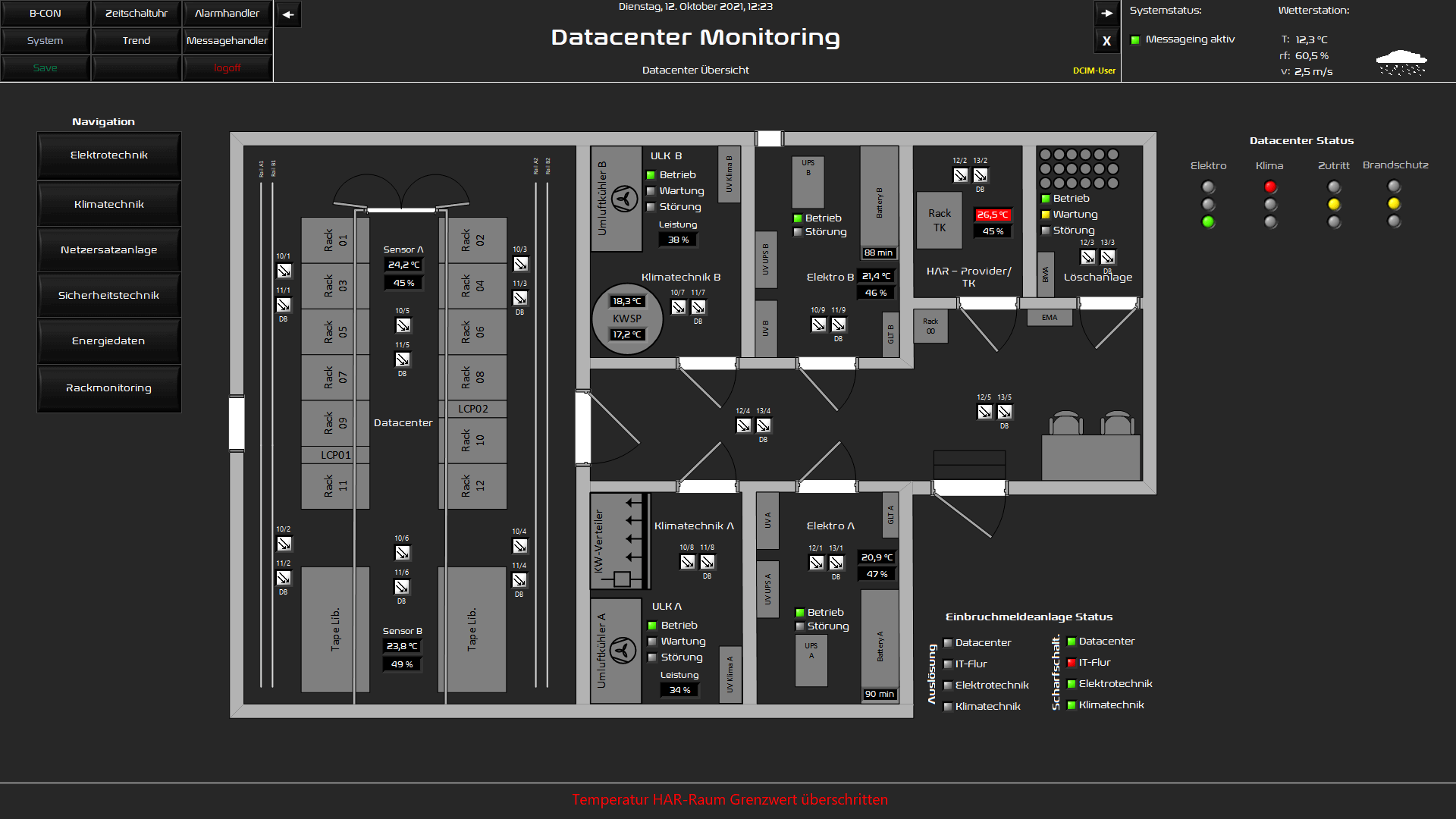
One challenge of datacenter monitoring, which has usually outgrown the actual datacenter operating concept, lies in the areas of responsibility of the infrastructure. The datacenter infrastructure, for example, is often the responsibility of facility management due to its proximity to supply technology. Often, a facility management that is characterised by classic facility processes and has been little trained and sensitised to datacenter operation may show strong differences in the awareness of requirements for a highly available IT operation. This raises the question of how strong the digital mindset and, for example, the use of building control technology and building automation already is, and can this know-how, which is similar in principle, be adapted accordingly to the monitoring of a datacenter. On the other hand, it is also fair to look at the IT side, where there is often a lack of awareness of the supply infrastructure. In which of these areas is the monitoring of a datacenter responsible? In addition to the technical prerequisites and framework conditions, high availability always requires an organisation and personnel competence that can evaluate, operate and take responsibility for datacenter operations. In the best case, there is no silo thinking between the departments, but rather a fluid division of labour and responsibility between IT and facility management in a joint datacenter team.
What is the use of a monitoring system that regularly rings the on-call staff out of bed with false alarms?
The reliability of the data as well as the processing, evaluation and subsequent sensible alarm management are fundamental for the acceptance of monitoring in the area of all service consumers. Thus, it is necessary to weigh up on the basis of a classification of events: what are information/notes, warnings and critical faults. The question arises as to what impact which status message can have or, even better, the top-down question: To avert which damage scenario do I need which data from my infrastructure?
Monitoring systems can very quickly provide a confusing amount of data points and metrics, which may only generate data garbage, increased licensing costs and system resource requirements, but offer no added value to the status assessment and later analysis. The rule here is: as little as possible, as much as necessary.
In a goal-oriented approach, one should therefore look at the business requirements hierarchically from top to bottom and define the necessary metrics from the resulting requirements, which allow the desired statement on the status of the system to be derived directly or in logical connection and dependence. A holistic approach is necessary here, as all IT-supported business processes and their connection to IT must be considered.

Which information for whom?
As in the hierarchy above, for each of these levels there are monitoring tools and applications that are specialised and established in the level. Few tools offer in-depth and detailed monitoring across levels. In practice, one often encounters the concept that each level is monitored by its own monitoring tool.
Depending on the size of the infrastructure and IT landscape, complexity can result in a large amount of information/metrics that must be processed, visualised and evaluated. In a control center, all relevant information can fill several large-format screens. In any case, the displayed information is helpful for the technicians and admins to get a quick overview of the status of the facilities and systems from a distance and to be able to assess the situation.
And here, too, there is a challenge. Does the CIO care what the temperatures or pressures are in the refrigeration circuit of the refrigeration equipment, as long as it is not a current problem? If the CIO is not personally interested, he will probably not want to deal with it. Therefore, a CIO's focus will be on the availability of applications or even on processes, as he is responsible for secure and available IT operations. This is where the familiar buzzwords like dashboard and KPI come into play. While the technician finds his joy in the detailed digital twin of the infrastructure, managers feel more at home in number and service-oriented dashboards. The tool Grafana, a web-based visualisation and dashboard solution, is ideal for this purpose. For different needs, dashboards can be designed very clearly, which visualise the respective required information, whether KPI or technical measured value, as a value display or graph.
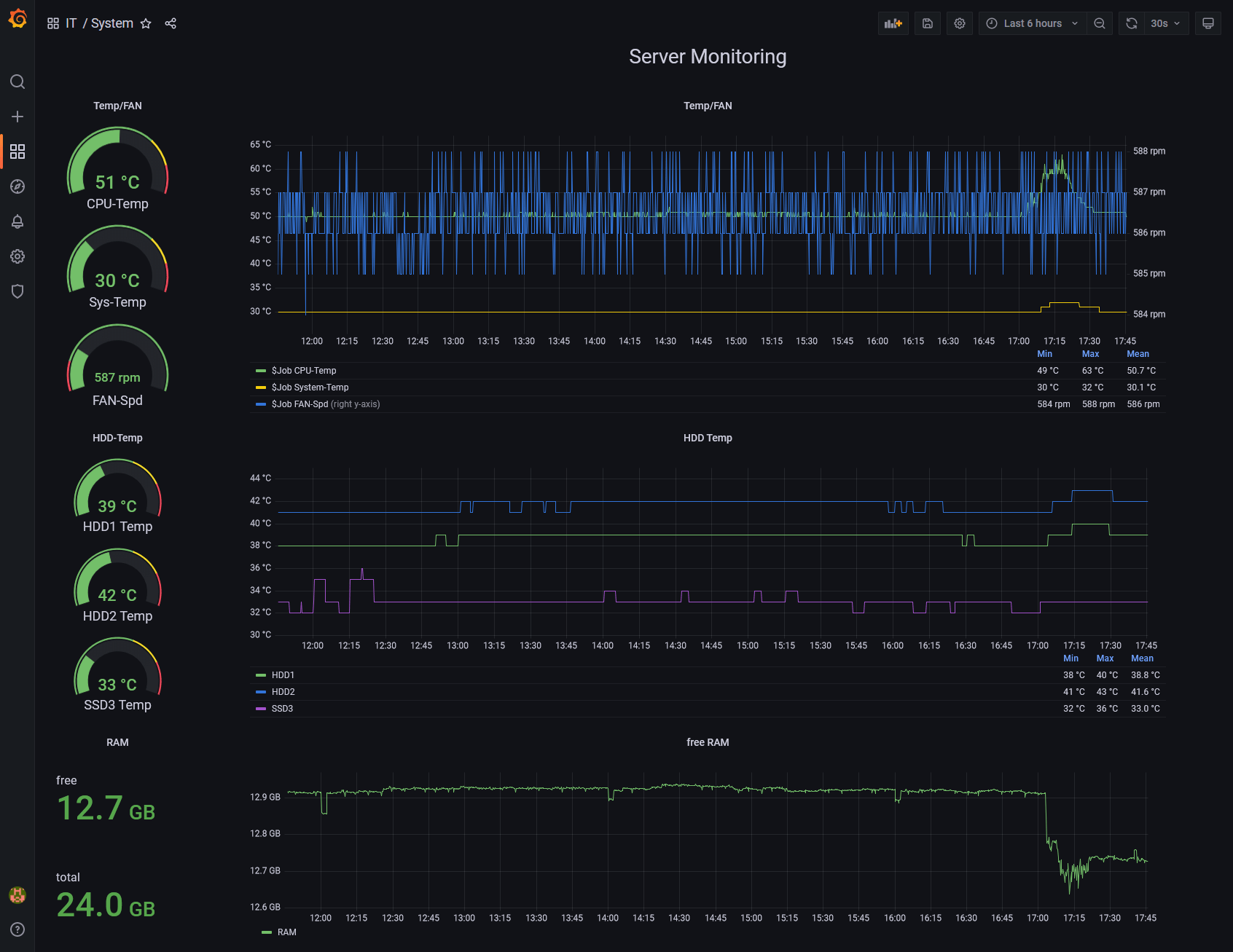
Costs, effort and benefits
What does a failure of IT services cost me and what does the integration and operation of monitoring cost me? How great is the probability of occurrence and how great is the damage? What are the points with which I can achieve the greatest effect with a low investment of resources?
From a business and economic point of view, these are always the key points that contribute significantly to decision-making in the context of risk management. These company-specific questions should be asked and discussed between management and IT operations. In some cases, it may also be helpful to seek objective and experienced support from external consultants.
On closer inspection, there are already tools and solutions in established and licensed products for a simple entry into the environment, which "only" need to be configured. For example, the SAP Solution Manager is already included in the SAP Business Support contract as an optimal monitoring tool for the SAP landscape. Many systems that are controlled via modern DDC or PLC controllers also offer alarming options, which is better than nothing in any case, but unfortunately has many disadvantages in terms of administration and transparency.
The good news is that there are some free, open source tools in the area of monitoring. Although these are mostly based on community support, they usually offer the full range of functions and can thus provide full-fledged monitoring. Support-based and licensable tools are supported by the manufacturer. The licence model is usually scalable and the costs are usually in the manageable range in relation to the known IT licence costs.
Despite the manageable investment costs for the tool, the integration, if the data is not already available in a well-documented format, is the part that causes the greater effort. If the necessary cabling for system connections or bus systems still has to be created in the datacenter infrastructure, this results in additional efforts and costs that are often overlooked.
Of course, the total effort depends significantly on the scope of visualisation and data points/metrics that are to be displayed, recorded and processed.
However, one will soon realise that the transparency gained about operating states and the ability to recognise plant behaviour, in normal as well as in fault conditions, represents real added value. In the analysis of the recorded trend data, deficits and optimisation potentials in the operation of the plants and systems can often be identified.
It is therefore not surprising that the datacenter standard EN50600 has also taken this topic into account in its sub-standards and that monitoring is assessed as an essential component for high availability, energy management and protection of a datacenter.
The recording of energy flows in the datacenter and the utilisation of IT systems provide information about inefficient or even unused systems that consume electricity in standby mode, among other things. A DCIM with integrated energy management is an ideal tool for source-related energy consumption billing. But monitoring can also be useful as a quality control tool in the need for proof of agreed SLAs, which IT may be subject to in its role as a service provider.
But monitoring should not be seen primarily as cost and energy control, rather it should be the tool to support the daily IT operations of a company. Ideally, the admin can see with a few glances where the problem lies in the IT landscape or the technician can analyse via remote access in on-call duty whether the network disturbance requires immediate action or was just a "network fluctuation" in the public supply network.
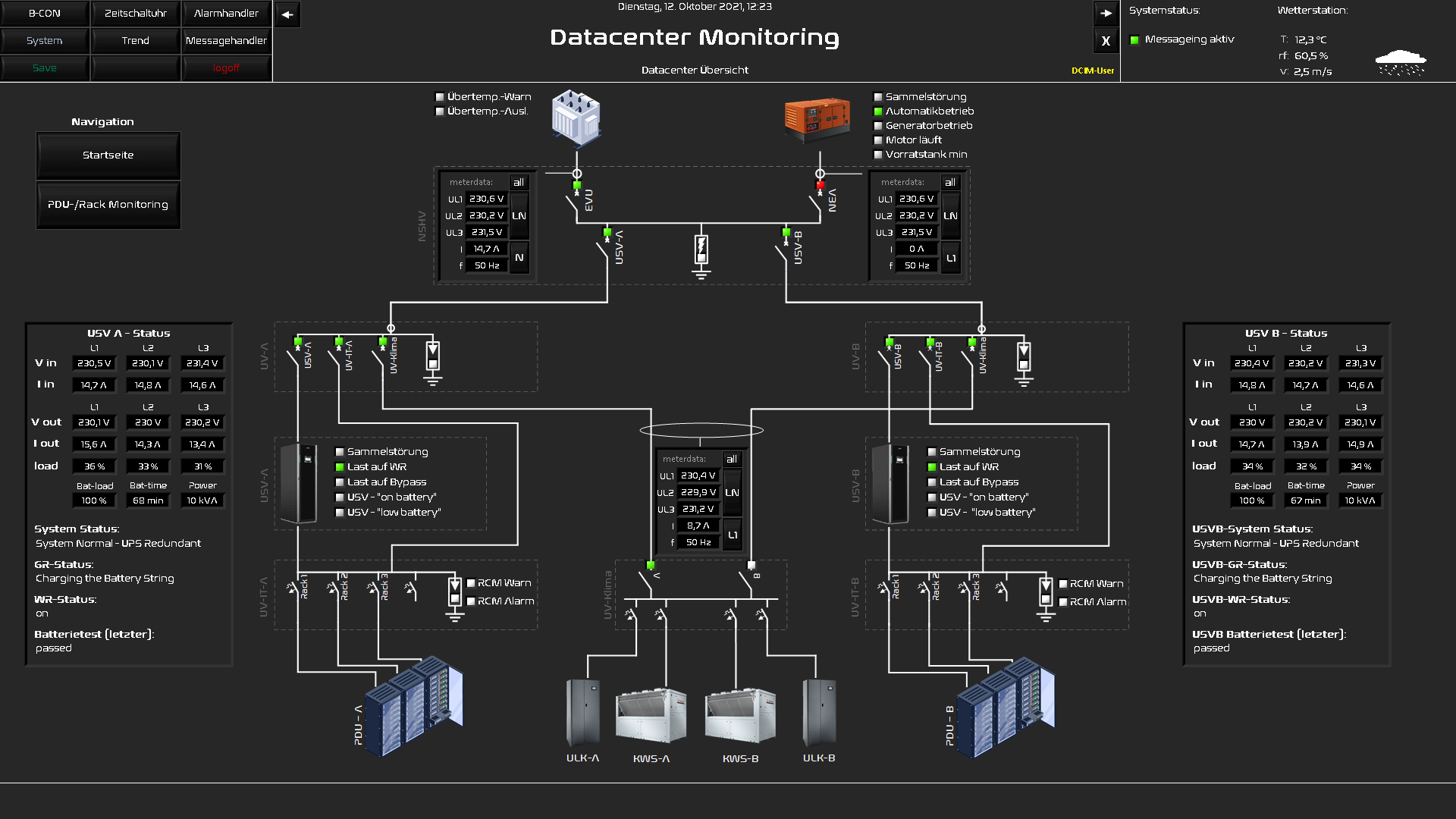
This makes monitoring as a central tool particularly important in the event of a disaster. In our opinion, monitoring should be the last system to "go out". Even in the event of a disaster, the system with alerting should be able to reliably display the status of the datacenter until the end in order to provide crisis management with useful information.
In technical implementation, we do not see the monitoring system as a virtualised server and with self-sufficient network components, which may also provide their own cabling up to the SMS gateway.
If the power supply of the datacenter is set up with two supply paths, the monitoring should also follow this redundant A-B supply concept and monitoring hardware should also be logically distributed to this A-B supply concept.
Basis for automation
Every type of automation requires sensory input data for a target-actual comparison. With this in mind, monitoring can be seen as a basic building block and subcomponent of automation, whether in the datacenter area, where additional systems may be switched on or off depending on temperatures, or in the IT infrastructure area, where additional containers or VMs can be activated to form a cluster depending on the load. In any case, these automatisms are triggered depending on measurement data and events that have been monitored. And also a proactive temporal activation of resources is based on measured known trend values of the past. In all cases, the actual value is determined for a known reference before an action is taken and actions or new target states are triggered using algorithms.
Conclusion
Anyone who wants to operate highly available and complex IT landscapes efficiently and securely can no longer do without monitoring. There will be no standard solution as a package, just as there is no IT landscape for your company. The possibilities and requirements are as individual as each company. Each infrastructure component and each standard shape the requirements and interfaces that a monitoring system should have. Besides the technology, the organisational structure around the IT operation is the component that is likely to have a significant impact on alerting and visualisation.
Since monitoring grows together with the entire infrastructure and IT systems during implementation, one should consciously ask questions about one's own requirements, alarm scenarios and the scope of the systems that are to be monitored before ambitiously introducing a system.
The establishment of a monitoring system, which first represents the greatest effort, is then followed by the operation and maintenance of the system. Here one must also be aware that there must always be adjustments and regular house keeping. But also the disciplined maintenance of metrics or systems that would trigger alarms in the context of conversions and maintenance is necessary and important to maintain the acceptance of the system. Unfortunately, once a monitoring system has reached the status of an annoying false alarm system, its acceptance and usefulness decreases.
Get in touch with us!
We look forward to your IT
We would also be happy to take on your IT together and develop strategic principles, design reliable system architectures, implement a sound basis and ensure modular, scalable, and highly available IT in your company - concerning SAP and beyond. Give us a call or send us an e-mail: We are excited to see what we can achieve together!